取代量化研究员?利用ChatGPT o1从量化论文自动回测交易算法¶
为了更好的了解社区的AI+量化项目,在这里我们探讨了一种新颖的AI辅助工作流程,旨在利用ChatGPT o1自动从量化金融文章中生成代码,并使用QuantConnect自动回测交易算法。探索AI与量化结合的最新前沿,欢迎关注公众号加入LLMQuant社区。
量化金融高度依赖于从广泛研究中得出的数据驱动策略。然而,将密集的学术论文中的见解转化为可执行的交易算法可能既耗时又容易出错。虽然立即创建一个可用于生产的解决方案可能并不现实,但我们的目标是在几秒钟内为QuantConnect生成样板代码。这个初始代码可以帮助确定一篇文章是否提出了值得进一步研究的有前途的策略,或者是否应该被忽略。
文章简介¶
我们将详细介绍如何运行此代码,并展示我们的初步测试。对于基础原理,本文可作为我之前作品“算法交易中的LLM配对编程”的补充。值得注意的是,我们的方法采用了线性工作流程,暂时搁置了双代理架构。该工具不仅从PDF文章中提取和总结了关键的交易策略和风险管理技术,还生成了语法正确的QuantConnect Python代码,并带有易于审阅的语法高亮。
初步测试表明,生成的代码是无错误的,尽管在所有测试中实现100%的准确性尚未实现。该工具的NLP组件采用了基本技术,未来可以进一步完善。然而,我选择迅速发布代码,作为这个快速发展的领域的概念验证。该项目正在进行中,未来将不断改进。让我们认为,今天我在这里描述的是它的beta版本。
工作原理¶
该自动化的核心是ArticleProcessor类,它组织了从PDF提取到代码生成的整个工作流程。以下是其功能的分解:
1. 使用pdfplumber进行PDF文本提取¶
流程从使用pdfplumber库加载和提取PDF文件中的文本开始。与其他PDF解析工具不同,pdfplumber提供了卓越的准确性,特别是对于学术文章中常见的复杂布局。
def load_pdf(self, pdf_path: str) -> str:
try:
text = ""
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
page_text = page.extract_text()
if page_text:
text += page_text + "\n"
logging.info("PDF加载成功。")
return text
except Exception as e:
logging.error(f"无法加载PDF:{e}")
return ""
2. 文本预处理¶
一旦提取了文本,清理和预处理就至关重要。这包括使用正则表达式删除URL、页眉、页脚、独立数字(如页码)和其他无关内容。
def preprocess_text(self, text: str) -> str:
try:
text = re.sub(r'https?://\S+', '', text)
text = re.sub(r'Electronic copy available at: .*', '', text)
text = re.sub(r'^\d+\s*$', '', text, flags=re.MULTILINE)
text = re.sub(r'\n+', '\n', text)
text = re.sub(r'^\s*(Author|Title|Abstract)\s*$', '', text, flags=re.MULTILINE | re.IGNORECASE)
text = text.strip()
logging.info("文本预处理成功。")
return text
except Exception as e:
logging.error(f"无法预处理文本:{e}")
return ""
3. 使用SpaCy进行标题检测¶
理解文章的结构至关重要。利用SpaCy的NLP功能,工具根据句子长度和标题格式等启发式方法识别章节标题。此分段有助于更有效地组织内容进行分析。
def detect_headings(self, text: str) -> List[str]:
try:
doc = self.nlp(text)
headings = []
for sent in doc.sents:
sent_text = sent.text.strip()
if len(sent_text.split()) < 10 and sent_text.istitle():
headings.append(sent_text)
logging.info(f"检测到{len(headings)}个标题。")
return headings
except Exception as e:
logging.error(f"无法检测标题:{e}")
return []
4. 章节拆分和关键词分析¶
在识别标题后,文本被拆分为相应的章节。然后,工具执行关键词分析,将句子分类为trading_signal和risk_management。这种分类基于预定义的相关关键词列表,确保只有相关信息被进一步处理。
def keyword_analysis(self, sections: Dict[str, str]) -> Dict[str, List[str]]:
keyword_map = defaultdict(list)
risk_management_keywords = [
"drawdown", "volatility", "reduce", "limit", "risk", "risk-adjusted",
"maximal drawdown", "market volatility", "bear markets", "stability",
"sidestep", "reduce drawdown", "stop-loss", "position sizing", "hedging"
]
trading_signal_keywords = [
"buy", "sell", "signal", "indicator", "trend", "SMA", "moving average",
"momentum", "RSI", "MACD", "bollinger bands", "Rachev ratio", "stay long",
"exit", "market timing", "yield curve", "recession", "unemployment",
"housing starts", "Treasuries", "economic indicator"
]
irrelevant_patterns = [
r'figure \d+',
r'\[\d+\]',
r'\(.*?\)',
r'chart',
r'\bfigure\b',
r'performance chart',
r'\d{4}-\d{4}',
r'^\s*$'
]
processed_sentences = set()
for section, content in sections.items():
doc = self.nlp(content)
for sent in doc.sents:
sent_text = sent.text.lower().strip()
if any(re.search(pattern, sent_text) for pattern in irrelevant_patterns):
continue
if sent_text in processed_sentences:
continue
processed_sentences.add(sent_text)
if any(kw in sent_text for kw in trading_signal_keywords):
keyword_map['trading_signal'].append(sent.text.strip())
elif any(kw in sent_text for kw in risk_management_keywords):
keyword_map['risk_management'].append(sent.text.strip())
for category, sentences in keyword_map.items():
unique_sentences = list(set(sentences))
keyword_map[category] = sorted(unique_sentences, key=len)
logging.info("关键词分析完成。")
return keyword_map
5. 使用OpenAI的GPT-4生成摘要和QuantConnect代码¶
利用OpenAI的GPT-4的强大功能,工具生成了提取策略和风险管理技术的简洁摘要。更令人印象深刻的是,它将这些见解转化为功能齐全的QuantConnect Python算法,确保它们遵循最佳实践和语法正确性。
def generate_qc_code(self, extracted_data: Dict[str, List[str]]) -> str:
trading_signals = '\n'.join(extracted_data.get('trading_signal', []))
risk_management = '\n'.join(extracted_data.get('risk_management', []))
prompt = f"""
你是一位专家级的QuantConnect算法开发者。将以下交易策略和风险管理描述转换为完整、无错误的QuantConnect Python算法。
### 交易策略:
{trading_signals}
### 风险管理:
{risk_management}
### 要求:
1. **Initialize方法**:
- 设置开始和结束日期。
- 设置初始资金。
- 定义选股逻辑。
- 初始化所需指标。
2. **OnData方法**:
- 根据指标实施买/卖逻辑。
- 确保指标正确更新。
3. **风险管理**:
- 实施15%的回撤限制。
- 应用所描述的头寸规模或止损机制。
4. **确保合规**:
- 仅使用QuantConnect支持的指标和方法。
- 代码必须语法正确且无错误。
### 示例结构:
```python
from AlgorithmImports import *
class MyAlgorithm(QCAlgorithm):
def Initialize(self):
self.SetStartDate(2020, 1, 1)
self.SetEndDate(2023, 1, 1)
self.SetCash(100000)
# 定义选股、指标等。
def OnData(self, data):
# 交易逻辑
def OnEndOfDay(self):
# 风险管理
```
### 生成的代码:
```
# LLM将在此行之后生成代码
```
"""
try:
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "你是一名专门用Python生成QuantConnect算法的助理。"},
{"role": "user", "content": prompt}
],
max_tokens=2500,
temperature=0.3,
n=1
)
generated_code = response['choices'][0]['message']['content'].strip()
code_match = re.search(r'```python(.*?)```', generated_code, re.DOTALL)
if code_match:
generated_code = code_match.group(1).strip()
logging.info("LLM生成了代码。")
return generated_code
except Exception as e:
logging.error(f"无法生成代码:{e}")
return ""
6. 使用Tkinter和Pygments显示结果¶
为了提供用户友好的体验,工具使用Tkinter在不同的窗口中显示文章摘要和生成的代码。Pygments库通过为Python代码添加语法高亮来增强可读性。
def display_summary_and_code(self, summary: str, code: str):
# 创建主Tkinter根
root = tk.Tk()
root.withdraw() # 隐藏主窗口
# 摘要窗口
summary_window = tk.Toplevel()
summary_window.title("文章摘要")
summary_window.geometry("800x600")
summary_text = scrolledtext.ScrolledText(summary_window, wrap=tk.WORD, font=("Arial", 12))
summary_text.pack(expand=True, fill='both')
summary_text.insert(tk.END, summary)
summary_text.configure(state='disabled') # 设为只读
# 代码窗口
code_window = tk.Toplevel()
code_window.title("生成的QuantConnect代码")
code_window.geometry("1000x800")
code_text = scrolledtext.ScrolledText(code_window, wrap=tk.NONE, font=("Consolas", 12), bg="#2B2B2B", fg="#F8F8F2")
code_text.pack(expand=True, fill='both')
# 应用语法高亮
self.apply_syntax_highlighting(code, code_text)
code_text.configure(state='disabled') # 设为只读
# 启动Tkinter事件循环
root.mainloop()
7. 初次测试¶
我们使用了L. Durian和R. Vojtko在Quantpedia上的文章《使用市场时机策略避免熊市》。输出结果如下:
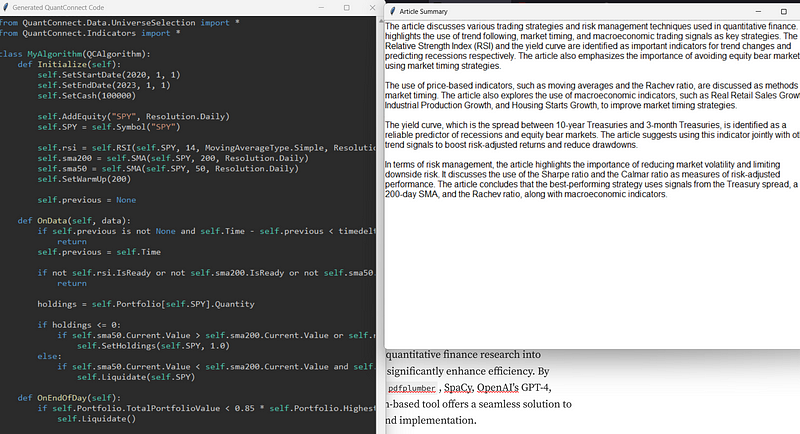
首次运行时生成的代码产生了以下回测结果:

我们可以看到,该算法在2020年处于空仓状态,正如预期的那样,避免了新冠疫情的熊市。该文章确实似乎成功地管理了熊市的规避,绝对值得进一步研究。
结论¶
将量化金融研究转化为可执行的交易算法的自动化可以显著提高效率。通过集成强大的库,如pdfplumber、SpaCy、OpenAI的GPT-4、Tkinter和Pygments,这个基于Python的工具提供了一个无缝的解决方案,弥合了研究和实施之间的差距。
意见
- 我们认为,将金融论文转化为交易算法的当前过程耗时且容易出错,强调了自动化的必要性。
- 强调了该工具的初步性质,作者承认虽然生成的代码基本无错误,实现完全准确性仍是未来开发的目标。
- 该工具能够将句子分类为交易信号和风险管理,被视为关键特性,确保只有相关信息用于代码生成。
- 使用GPT-4生成代码被认为特别具有创新性,展示了AI在量化金融领域的潜力。
- 我们对项目的持续改进和其成为量化分析师和交易员的宝贵资产的潜力持乐观态度。
- 使用Tkinter创建用户友好的界面,并使用Pygments进行语法高亮,表明了对用户体验和生成代码可读性的关注。