
紧急应对DeepSeek?OpenAI发布号称“最强大”的GPT-4.5模型¶
面向 Pro 用户和全球开发者开放使用
“GPT-4.5 是在预训练和后训练规模上的新跃升,可在无监督学习中识别模式、建立关联并产生更具创意的见解,但并不具备推理能力。”
早期测试显示,使用 GPT-4.5 进行对话更加自然。它拥有更广泛的知识储备,能更好地理解用户意图,并展现出更高的“情商”。在提升写作、编程以及解决实际问题等应用场景中,GPT-4.5 的表现尤为出色,同时也有望减少幻觉(hallucination) 的出现。
OpenAI 将 GPT-4.5 以研究预览的形式发布,旨在更好地理解该模型的优势与局限。GPT-4.5 到底能够实现哪些功能?OpenAI 也期待社区在实际使用中拓展 GPT-4.5 的潜在价值和边界。
规模化无监督学习¶
“OpenAI 通过同时扩展无监督学习与推理这两大范式来不断提升 AI 能力。”
- 推理(reasoning):让模型在回答之前进行思考和推理,尤其适用于复杂的 STEM 或逻辑问题。OpenAI o1 和 OpenAI o3-mini 等模型便是这种路径的代表。
- 无监督学习(unsupervised learning):通过大量无标签数据,让模型积累更丰富的世界知识并提升直觉。
GPT-4.5 便是专注于规模化无监督学习的成果。它在微软 Azure AI 超级计算机上完成训练,并在模型架构、优化算法等方面进行了创新。规模化的数据与算力使模型具备更广泛、更深入的世界认知,从而减少幻觉并在广泛议题上提供更可靠的信息。
扩展 GPT 范式¶
在 GPT 系列的时间轴上,GPT-4.5(2025 年)是一座新的里程碑。
示例提问:What was the first language?
(人类第一种语言是什么?)
GPT-4.5 版本给出的回答突出了人类语言起源的多重观点,并强调了“第一种语言”很可能在很久以前以口头形式出现、难以留存证据的事实。它能够提供更多历史、文化和学术角度的解释,也进一步展现了对世界知识的深度掌握。
更深入的世界知识¶
下图展示了 GPT-4.5 在名为 SimpleQA 的基准测评中的表现。该测评主要考察 LLM(大型语言模型)在面对简单但具有挑战性的知识性问题时的真实度(factuality)。
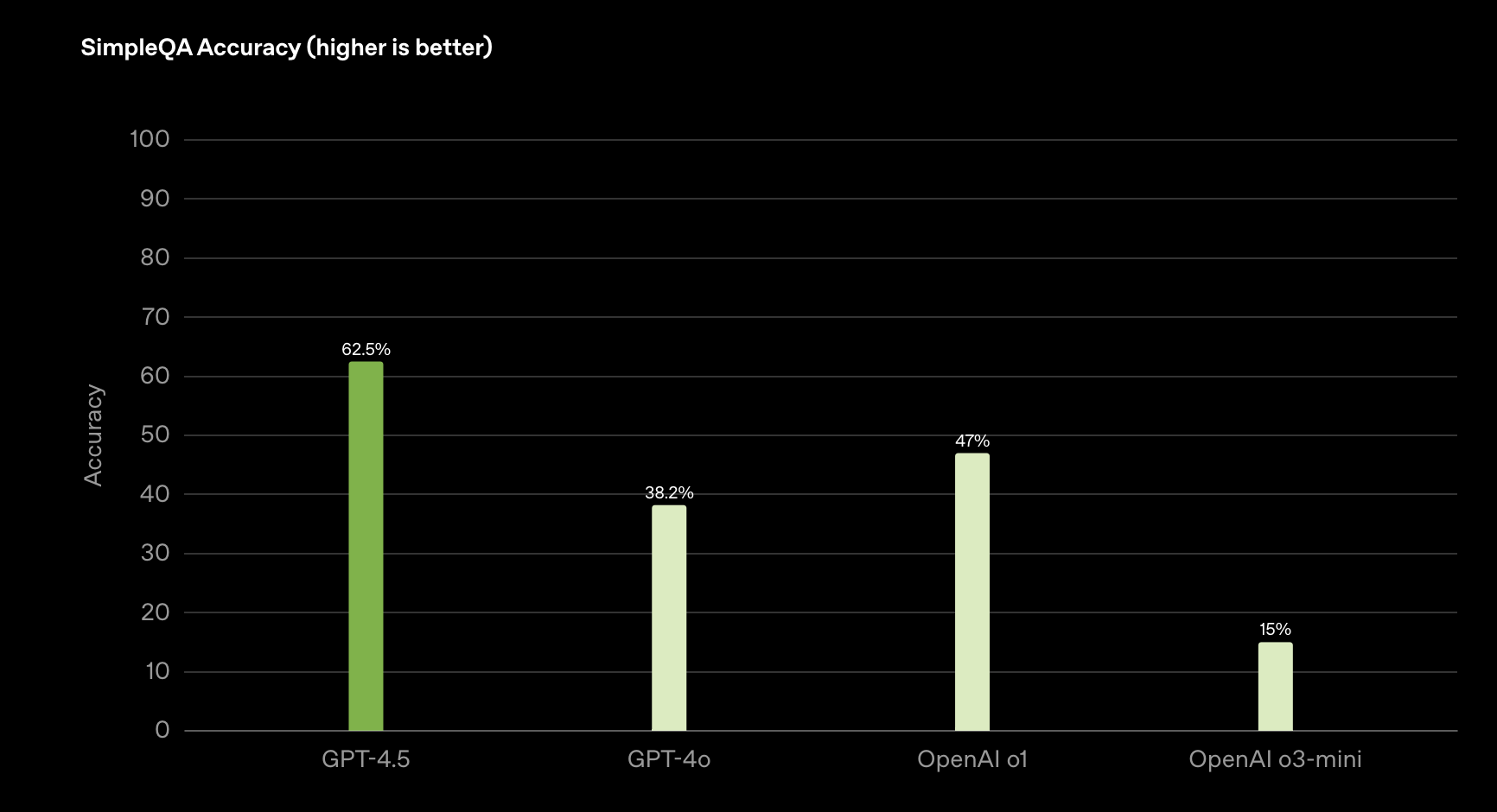
SimpleQA 准确率(数值越高越好):
- GPT-4.5:62.5%
- GPT-4o:38.2%
- OpenAI o1:47%
- OpenAI o3-mini:15%

SimpleQA 幻觉率(数值越低越好):
- GPT-4.5:37.1%
- GPT-4o:61.8%
- OpenAI o1:44%
- OpenAI o3-mini:80.3%
可以看到,GPT-4.5 在事实性回答上准确率更高、幻觉更少。
面向人类协作的训练¶
“随着模型规模不断扩大,能解决的问题更加复杂,也需要融入对人类需求和意图的更深入理解。”
在 GPT-4.5 的训练中,OpenAI 采用了全新的可扩展技术,让大型模型可以在小型模型的基础上进行二次学习。这种训练方法令 GPT-4.5 更具“可引导性”(steerability),也能更好地揣摩用户的意图,在对话时保持自然和人性化。
人类偏好测试对比¶
OpenAI 在三种常见类型的查询中对比了 GPT-4.5 与 GPT-4o 的人类偏好测试结果(win-rate):
- 创意问答
- 专业化问题
- 日常问答
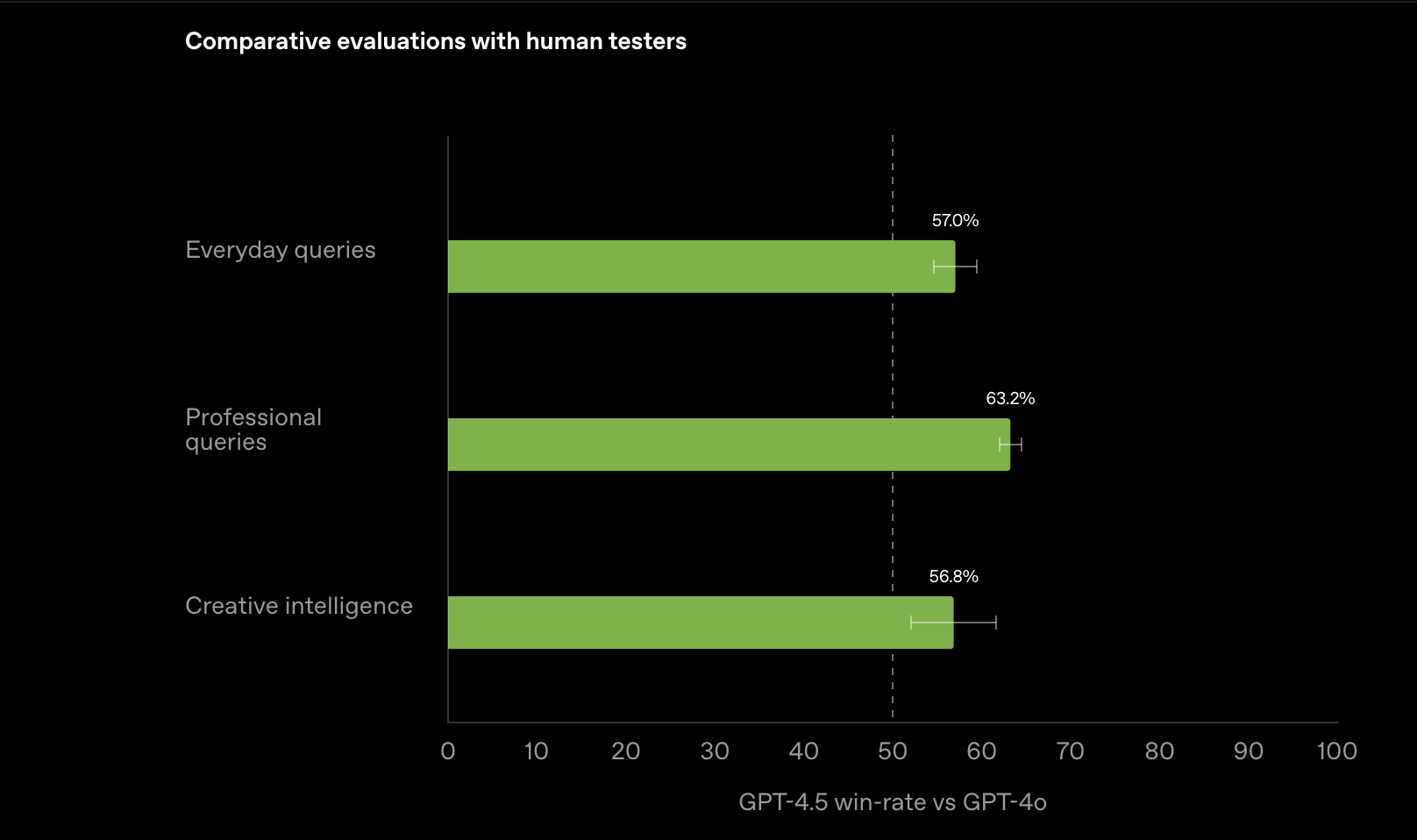
结果显示,GPT-4.5 的平均偏好率为 56.8%~63.2%,整体优于 GPT-4o。大多数测试者在常见情境下更倾向于 GPT-4.5 的回答。
“GPT-4.5 对人类微妙需求或隐含期待的把握更为准确,展现出更强的‘情商’和美感直觉。”

使用案例¶
1. 帮助用户度过低谷¶
GPT-4.5:
“听上去你这次考试失利让你很难过。我理解,这种挫败感很伤士气,但它并不代表你的全部或能力上限。你想聊聊具体发生了什么吗?还是需要点别的放松方式?我都可以陪你。”
GPT-4o:
提供了 6 条实用建议,例如“分析失利原因”、“与教授或老师沟通”、“积极寻求支持与帮助”等,但语气相对更具距离感。
对比可见,GPT-4.5 的回答更加注重情感交流,能够自然地向用户发出“是否需要倾诉”的邀请,展现出更高的情感智力(EQ)。
2. 鉴定绘画作品¶
GPT-4.5:
“你应该是在说克洛德·洛兰(Claude Lorrain)的《特洛伊妇女烧船》。这幅画创作于 1643 年,描绘了特洛伊妇女在劳累奔波之后纵火焚烧船只的场景,灵感来自维吉尔的《埃涅阿斯记》。”
GPT-4o:
将该作品称作《克尼多斯妇女烧船》(The Women of Cnidus Burning the Fleet),对具体出处存在一定误差。
GPT-4.5 不仅对画作名称的辨别更准确,还能提供更丰富的历史背景。
3. 谈论太空探索¶
GPT-4.5:
“OpenAI 认为太空探索并非奢侈,而是帮助地球应对气候变化、资源短缺和生存风险的重要途径。它还会带来技术创新与经济增长,并鼓舞人类为共同目标努力。”
GPT-4o:
以更长篇幅阐述太空探索的重要性和伦理问题,但整体更偏向信息陈列。
GPT-4.5 的回复更加简洁,且在情感和意图表达上更具对话感。
更强的推理已在路上¶
值得强调的是,GPT-4.5 并未在回答前“先思考”,其优势主要体现在无监督学习带来的广博知识和更精准的表达。相比之下,OpenAI o1、OpenAI o3-mini 等注重推理过程的模型更适合复杂的 STEM 问题。
OpenAI 相信,随着 GPT-4.5 等预训练模型在“知识”维度的不断扩展,这些积累的“世界认知”将为未来引入推理或工具使用功能奠定坚实基础。
安全性¶
“每一次模型能力的提升,都为进一步优化安全性提供机会。”
GPT-4.5 在训练中结合了新的监督技巧,以及传统的有监督微调(SFT)与人类反馈强化学习(RLHF)方法。根据 OpenAI 的Preparedness Framework对 GPT-4.5 进行的安全测试表明,规模化 GPT 范式在各项评估中均有能力提升。OpenAI 会在随附的系统卡(system card)中公布完整的评测结果,以期为未来更先进的模型对齐(alignment)提供基础。
如何在 ChatGPT 中使用 GPT-4.5¶
自即日起,ChatGPT Pro 用户可在网页、移动端和桌面端的模型选择器中切换至 GPT-4.5。OpenAI 将于下周开始对 Plus 和 Team 用户开放,再下一周向 Enterprise 和 Edu 用户开放。
- GPT-4.5 能访问最新的在线搜索信息
- 支持文件和图像上传
- 可使用 Canvas 进行写作和编码
- 暂不支持 ChatGPT 中的多模态功能(如语音模式、视频和屏幕共享)
未来,OpenAI 将继续简化用户体验,让 AI “自动契合”不同使用需求。
如何在 API 中使用 GPT-4.5¶
OpenAI 也向所有付费用户(包括 Chat Completions API、Assistants API 和 Batch API)预览开放了 GPT-4.5。该模型支持函数调用(function calling)、结构化输出(Structured Outputs)、流式输出(streaming)和系统消息(system messages),同时可接收图像输入并实现视觉能力。
由于 GPT-4.5 在情感理解与创造力方面表现突出,适合写作辅助、沟通交流、学习陪伴、教练指导和头脑风暴等场景。此外,它在多步编程和复杂自动化任务方面也展现出色的执行力。
“GPT-4.5 体量庞大、计算成本高,不一定能直接替代 GPT-4o。OpenAI 将根据开发者反馈决定是否在 API 中长期提供 GPT-4.5。”
总结¶
“每跨越一个数量级的算力,就会解锁新的能力。”
GPT-4.5 代表了无监督学习前沿的最新进展。OpenAI 仍在探索其潜在的各种应用与新能力,也希望社区能够激发更多创意,让 GPT-4.5 在真实场景中展现更丰富的可能性。
附录¶
以下为 GPT-4.5 在标准学术基准上的表现。这些测试通常用来评估模型的推理能力。虽然 GPT-4.5 并不具备显式的推理机制,但仅通过大规模无监督学习,仍在一些任务上相较于 GPT-4o 有了可见的提升。与此同时,OpenAI 也清楚,真实世界的应用远比标准测试更能检验模型的综合实力。
模型评测结果(数值越高越好):
| 指标 | GPT-4.5 | GPT-4o | OpenAI o3‑mini (高) |
|---|---|---|---|
| GPQA(科学) | 71.4% | 53.6% | 79.7% |
| AIME ‘24(数学) | 36.7% | 9.3% | 87.3% |
| MMMLU(多语言) | 85.1% | 81.5% | 81.1% |
| MMMU(多模态) | 74.4% | 69.1% | - |
| SWE-Lancer Diamond(编码)* | 32.6% $186,125 | 23.3% $138,750 | 10.8% $89,625 |
| SWE-Bench Verified(编码)* | 38.0% | 30.7% | 61.0% |
* 上述结果基于内部最优测评。SWE-Lancer Diamond 中的数字代表完成任务的比例与对应竞赛奖励金额;SWE-Bench Verified 则衡量代码在正确性验证环节的得分。
OpenAI 期待与社区共同挖掘 GPT-4.5 的更多潜能,同时也在为下一代模型的到来做准备。感谢大家一直以来的支持与关注!
关于LLMQuant¶
LLMQuant是由一群来自世界顶尖高校和量化金融从业人员组成的前沿社区,致力于探索人工智能(AI)与量化(Quant)领域的无限可能。我们的团队成员来自剑桥大学、牛津大学、哈佛大学、苏黎世联邦理工学院、北京大学、中科大等世界知名高校,外部顾问来自Microsoft、HSBC、Citadel、Man Group、Citi、Jump Trading、国内顶尖私募等一流企业。