
InvestorBench:面向LLM金融决策任务的Benchmark¶

在近期的研究中,基于大语言模型(LLM)的智能体在复杂且开放式的环境中展现出优异的决策能力,覆盖了金融交易等多个应用场景(Zhang et al. (2024b); Guo et al. (2024); Eigner and Händler (2024); Wang et al. (2024))。然而,针对金融领域特定的交易决策需求,如何构建适配于多种金融任务的多模态LLM智能体框架仍然面临较大挑战。这主要源于金融市场的高波动与多样性:智能体不仅需要捕捉高时效性的核心交易信号,还要在信息模态杂糅、行情瞬息万变的环境下持续做出高质量决策。
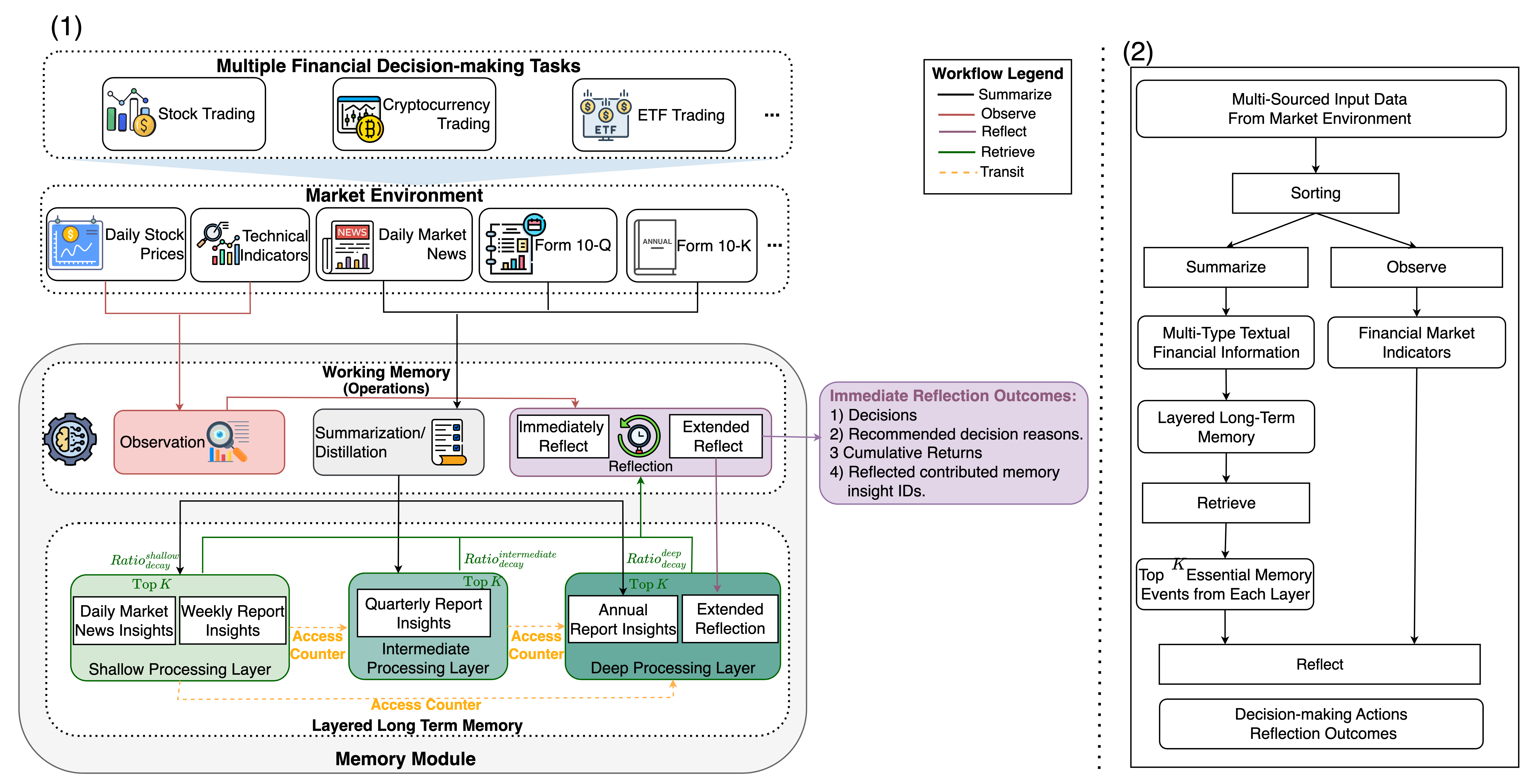
Figure 1: InvestorBench框架的整体架构示意图。
此外,随着应用场景从单一标的扩展至多种金融任务,金融决策中影响要素也会随任务类型而变得复杂多样。例如,单只股票交易需侧重公司和行业层面的基本面与财报数据(Yi et al. (2022));而加密货币交易更易受到即时新闻与市场情绪的驱动(Bhatnagar et al. (2023));至于ETF,往往注重的是长期资产配置与被动投资策略(Madhavan (2016))。
虽然近期陆续出现了一系列针对单一金融场景的LLM智能体框架,如FinMem(Yu et al. (2024a))、FinAgent(Zhang et al. (2024a))、CryptoTrade(Li et al. (2024))、FinRobot(Yang et al. (2024))和FinCon(Yu et al. (2024b))等,但这些方案往往只聚焦于单一或少数几种金融任务,且大都依赖私有数据,难以进行横向对比评估。因此,当前亟需一种面向多任务场景的开放式Benchmark,既能统一评测LLM智能体在不同金融决策任务中的表现,也能助力多模态数据和不同模型的公平比较。

为此,我们提出InvestorBench:一个面向多元金融决策任务的开源Benchmark体系。该框架基于FinMem(Yu et al. (2024a))的多层记忆结构思路加以拓展,覆盖了股票交易、加密货币交易和ETF投资三大核心领域,并提供了多源数据环境。与传统依赖相似度检索(FinAgent等)的方法相比,FinMem式的分层记忆与多速率衰减机制可使LLM智能体对多时效性、多模态信息进行更有效的融合和权衡,既能强化关键性长期信息,也可对短期交易信号实时响应。此外,InvestorBench还配套了多条数据源与评测指标,为研究者和实践者打造了一套统一且可扩展的评测平台。
我们的主要贡献:
- 建立了InvestorBench——首个兼具多任务、多模态数据来源的LLM金融决策Benchmark,帮助评测LLM智能体在复杂、开放式金融场景中的推理与顺序决策能力。
- 提供了开放的多源金融环境(股票、加密货币、ETF),并辅以相关API与数据仓库,保证了评测的可重现性和可拓展性。
- 提出了一套统一且灵活的LLM-Agent框架,可以轻松替换不同LLM作为大脑核心。本研究中,我们测试了包含通用LLM、金融领域微调LLM等在内的13种模型,对其在三大金融决策任务中的表现进行了系统评估。
引言¶
大语言模型(LLM)已在众多复杂场景中的决策任务中取得了令人瞩目的成绩(Zhang et al. (2024b); Guo et al. (2024); Eigner and Händler (2024); Wang et al. (2024))。然而,将其应用于金融领域仍充满挑战:金融市场高度波动、噪音多、时效性强,且数据类型丰富(数值、文本、宏观指标、情感分析等)。智能体要做到准确交易,需要在部分可观测 (POMDP) 环境下捕捉信息并连续做出高质量决策(Bertsekas and Shreve (1996); Liu et al. (2020); Kabbani and Duman (2022))。
设计多任务金融智能体更是难上加难:
不同金融产品有不同侧重点——股票需要行业财报和基本面;加密货币则对即时新闻及情绪尤为敏感;ETF更看重长期组合的成本与配置策略。因此,统一评测LLM智能体在不同金融任务下的适应力与决策质量,成为当前研究的一个关键需求。
近期涌现的金融领域LLM多智能体框架,如FinMem、FinAgent、CryptoTrade、FinRobot、FinCon等,为特定场景提供了不同思路:
- FinRobot专注于市场分析;
- FinMem与FinAgent主要面向股票/ETF交易;
- CryptoTrade仅覆盖加密货币;
- FinCon涉足多资产组合管理,但规模还局限于少量股票。
局限: 多数框架只针对有限类型的金融决策任务,缺少通用性;且常依赖私有数据,给后续评测与复现带来困难。
InvestorBench正是在此背景下提出的:它在FinMem的“分层记忆+多速率衰减”基础上进一步扩展,引入多种金融市场环境,以统一评估LLM-Agent在多任务决策下的表现。其特点包括:
- 多层次记忆:区别于FinAgent的纯文本相似检索,InvestorBench继承了FinMem的分层记忆结构,不同层次区分不同时间衰减速率,保证了时效性与长期记忆的平衡;
- 覆盖三大任务:股票交易、加密货币交易、ETF投资;
- 开放式多模态数据源:涵盖行情、新闻、公司财报、情绪、宏观数据等多方面。
小结¶
- 提出InvestorBench这一“金融多任务LLM”开放式Benchmark,面向复杂、开放式金融场景下的LLM智能体评测;
- 提供多来源的真实数据环境,并可与任意LLM-agent设计结合;
- 系统测试了13种LLM(含闭源、开源以及金融微调模型),展示了它们在金融顺序决策中的性能差异。
LLM交易智能体¶
在本节中,我们将介绍InvestorBench提供的LLM智能体框架,并基于部分可观测马尔可夫决策过程 (POMDP) 对金融决策任务进行形式化描述(Bertsekas and Shreve (1996); Liu et al. (2020); Kabbani and Duman (2022))。
2.1 定义¶
InvestorBench中的LLM智能体由若干子模块构成,旨在模拟或超越专业投资人的投研能力:
- Brain/Backbone(LLM本体):智能体核心,用于理解和生成自然语言,支持复杂推理及对市场信息的解读(如做出行情预测、复盘等)。
- Perception:感知模块,将原始市场数据(数值、文本、图像等)转换成适合LLM处理的结构化格式。
- Profile:角色和任务背景描述。
- 角色:设定为资深投资人,具备某种动态风险偏好(如在市场趋势向好时更具进取性,反之更保守)。
- 任务背景:标的资产的关键信息(历史走势、行业概况、产品特征等)。
- Memory:记忆模块,用于存储和检索历史市场信息与推理经验。
- Working Memory:主要进行当前观测、摘要和即时反思;
- Layered Long-term Memory:采用多层结构+不同衰减速率的记忆机制,保证长、中、短期信息的区分及优先级管理。
- Action:执行具体交易指令,根据LLM输出选择"Buy"、"Sell"或"Hold",并结合盈亏记录、风险反馈等生成下一步决策。
2.2 金融决策建模¶
将金融交易视作一个无限时域POMDP,时间索引记为 $ \mathbb{T} = {0,1,2,\dots} $,折扣因子 $ \alpha \in (0,1] $。
- 状态空间:$ \mathcal{X} \times \mathcal{Y} $,其中 $ \mathcal{X} $ 为可观测部分(如行情价格等),$ \mathcal{Y} $ 为不可观测部分(如市场心理)。
- 行动空间:$ \mathcal{A} $,即 $ {\text{Buy}, \text{Sell}, \text{Hold}} $。
- 收益函数:$ \mathcal{R}(o,b,a) $,这里直接用每日盈亏(PnL)。
- 观测过程:$ {O_t} \subseteq \mathcal{X} \(,**反思过程**:\) {B_t} \subseteq \mathcal{Y} $,在此表示LLM智能体的自我回顾/推理。
- 策略:$ A_t \sim \pi(\cdot|\text{prompt}) $,LLM将prompt视作条件,输出交易指令。
令 $ R_t^\pi = \mathcal{R}(O_t, B_t, A_t) $ 为时刻 \(t\) 的收益,则该金融决策的目标函数为:
InvestorBench¶
接下来,我们介绍InvestorBench框架的整体设计,如图1所示。
3.1 Benchmark组成¶
InvestorBench由四大部分构成:
- 数据源与市场环境:整合了开源数据与第三方API(如Yahoo Finance、SEC EDGAR等),为模型搭建一个多模态市场环境数据仓库。
- LLM Agent:配备Brain、Perception、Profile、Memory、Action等子模块,并可使用外部工具(表格解析、API调用等)进行数据操作(向量数据库管理、信息强化与检索)。
- 金融决策任务:针对三种资产类型(股票、加密货币、ETF)分别提供交易场景。
- 评估指标:使用金融领域常见量化指标(如累积收益CR、夏普比率SR等)来衡量LLM智能体的表现。
3.2 交易环境¶
我们针对三类任务(股票、加密货币、ETF)分别构建了三套开放数据集,致力于提供完整的行情-新闻-情绪一体化评测环境。
- 股票环境
- 股价OHLCV:每日开盘价、高低价、收盘价、成交量等,来自Yahoo Finance。
- 公司财报摘录:10-Q、10-K等,下载自SEC EDGAR。
- 新闻:2020-07-01到2021-05-06期间,每日收集7只股票相关新闻。部分来自Zhou et al. (2021)的数据,另有特斯拉、苹果等则来自Refinitiv Real-Time News。
-
情绪:对新闻文本使用gpt-3.5-turbo-0125进行正面/负面/中性分类。
-
加密货币环境
- OHLCV数据来自CoinMarketCap。
- 多源加密新闻来自cryptonews、cryptopotato、cointelegraph (Vanhoucke (2023)),以及Zhou et al. (2021)的另一份数据集;
-
情绪同样由gpt-3.5-turbo-0125生成。
-
ETF环境
- 基于NIFTY数据集(Saqur et al. (2024)),包含2019-07-29到2020-09-21期间的ETF相关新闻头条及对应情绪标签。
实际回测中,我们会根据日期分割数据——在“训练/预热期”让智能体构建记忆数据库;在“测试期”评估最终绩效。
3.3 评估指标¶
我们选用四个常见指标:累积收益 (CR)、夏普比率 (SR)、年化波动率 (AV)以及最大回撤 (MDD)。其中CR和SR通常被视为核心指标:CR反映长期收益水平,SR测度风险收益比。
表格1列举了InvestorBench中所测试的13个LLM,包括闭源API、开源以及金融领域微调模型。
实验与结果¶
我们对三类单资产交易场景(股票、加密货币、ETF)进行测试,对比了开源模型、闭源模型以及金融领域专用模型的表现。为保证公平,我们统一了实验设置与评估指标,每个模型在相应回测区间内进行多次重复实验,取中位数指标。
4.1 实验设置¶
- 基准策略:股票与加密货币的对比基线为“Buy & Hold”,ETF也可用相同思路或等权组合。
- 温度参数:LLM-Agent系统统一设为0.6,兼顾一致性与创造性。
- 回测区间:
- 股票:预热2020-07-01至2020-09-30,测试2020-10-01至2021-05-06;
- 加密货币:预热2023-02-11至2023-04-04,测试2023-04-05至2023-11-05;
- ETF:预热2019-07-29至2019-12-30,测试2020-01-02至2020-09-21。
- 模型部署:基于vllm搭建;小于10B参数的模型用2张RTX A6000 GPU部署,中等(10-65B)用4张RTX A6000,大于65B则用8张A100 80GB。
4.2 结果一:股票交易¶
表2展示了13种模型在7只股票上的交易表现及平均值。图3(a)与图3(b)则进一步对不同类别、不同参数规模进行可视化对比,综合得到以下结论:
-
闭源模型在股票交易中表现更佳
相较开源或金融微调模型,闭源(如GPT-4家族、GPT-o1-preview等)整体CR、SR均显著更高且更稳定。说明尽管有些模型在财务文本上进行过微调(如Palmyra-Fin-70B),在连续交易决策场景中并没占明显优势,或许是因为它们主要面向长文本解读而非强化顺序决策。
-
参数规模的提升可显著增强推理及稳健性
在开源模型中,大于67B参数的LLM平均CR和SR优于中小模型,并且方差更小(见图3(b))。这与常见结论一致:LLM的推理能力随参数规模提升,对这种高度不确定的股票交易任务也同样成立。
-
闭源LLM在波动较高、信号混杂的市场环境中更具优势
测试期中,TSLA、NIO价格波动剧烈,市场多空交织;其余标的多为单边上涨。我们观察到,闭源模型在处理波动较大的标的时能更好地融合历史动量、持仓情况以及自我反思等信息,做出更准确决策。而大规模开源模型虽然也具备一定适应力,但相对稍逊。
4.3 结果二&三:加密货币交易与ETF交易¶
在加密货币及ETF交易场景中,市场趋势也呈现一定的混合多头/震荡状态。加密货币波动相对较小,而ETF则有更明显的价格起伏。主要观察如下:
-
捕捉加密货币交易信号需要大规模开源LLM或闭源模型
表3所示,小规模或中等规模开源模型在CR和SR上普遍不及Buy & Hold基线,说明对这类高度敏感且情绪驱动的加密市场,LLM需要足够的推理复杂度才能跟上节奏。
-
ETF投资更依赖强大的通识预训练模型
表4显示,ETF场景下,闭源模型在CR、SR等多指标上大幅领先其他模型。这可能是因为ETF交易通常需要跨行业、跨板块的宏观逻辑和长期策略;模型若没有大量预训练知识,难以发掘其中的关键信号。
4.4 讨论¶
综合来看,LLM在不同资产类别的交易表现差异显著,这既反映了金融市场的复杂性,也凸显了模型选择或微调的重要性。一般来说,闭源LLM因其底层训练规模庞大、参数丰富,在股票与ETF等多场景下都具备更强推理能力。开源模型若要竞争,需要进一步扩大参数规模或针对顺序决策做强化微调。此外,LLM-Agent能否灵活地“记忆”历史态势,并进行动态风险评估,也极大影响了其在不同市场环境下的稳健性。多层记忆、风险自适应等设计对复杂场景确有价值。
相关研究¶
5.1 金融领域的大语言模型¶
通用语言模型的快速发展激发了金融领域专用模型的研究,如FinBert(Liu et al. (2021); Yang et al. (2020))、FinGPT(Liu et al. (2023))、FinMA(Xie et al. (2023))、BloombergGPT(Wu et al. (2023))等。这些模型在海量金融数据上预训练或微调,以适应专业术语及金融任务需求。同时,LLM的崛起也推动了金融多智能体在交易、投研中的应用,如FinMem(Yu et al. (2024a))、FinAgent(Zhang et al. (2024a))等。但不同框架在任务范畴、数据类型上差异较大,使得对这些LLM-Agent的综合评估尚缺统一标准。
5.2 金融LLM基准¶
现有针对金融NLP的通用基准,如FLUE(Shah et al. (2022))涵盖情感分析、新闻分类、实体识别等五个任务;Pixiu(Xie et al. (2023))和FinBen(Xie et al. (2024))也扩展了多模态、文档理解等。但它们多集中在静态NLP任务,尚未对LLM智能体在实时交易、连续决策场景进行评测。InvestorBench则专注于动态、多步决策的测试,填补了该空白。
结论¶
InvestorBench为研究者提供了两种主要使用方式:
- 模式一:将自有或微调后的LLM接入InvestorBench的Agent框架进行多任务决策,并与我们提供的模型结果对比;
- 模式二:直接调用InvestorBench的环境与评估接口,将其集成到自定义Agent中,对比不同Agent设计的有效性。
这为在多样化真实环境中深入探索LLM金融决策能力提供了灵活平台。
展望:未来我们将扩展更丰富的数据模态(如音频财报电话会议、图形K线等),并在保持框架易用性的同时,探索其在多资产组合与更长时间跨度下的应用潜力。
Limitation¶
- 目前InvestorBench主要针对单资产决策任务,尚未覆盖多资产组合管理;
- 受版权限制,部分数据质量可能受限,或对模型评估有一定影响。
关于LLMQuant¶
LLMQuant是由一群来自世界顶尖高校和量化金融从业人员组成的前沿社区,致力于探索人工智能(AI)与量化(Quant)领域的无限可能。我们的团队成员来自剑桥大学、牛津大学、哈佛大学、苏黎世联邦理工学院、北京大学、中科大等世界知名高校,外部顾问来自Microsoft、HSBC、Citadel、Man Group、Citi、Jump Trading、国内顶尖私募等一流企业。