
全面科普:谷歌 Gemini Flash 2.0 与 DeepSeek R1、OpenAI o3-mini 的对比与应用¶

近年来,随着深度学习与自然语言处理技术的蓬勃发展,大型语言模型(LLM)在多语言文本理解、信息提取、推理与创作方面展现出前所未有的潜力。市面上涌现了各种性能与价格层次不一的模型,在选择合适的模型时需要综合考量多个指标,例如:准确度、速度、上下文窗口大小、成本以及适用场景等。以下内容将更为详细地对比来自谷歌、DeepSeek 与 OpenAI 的三大模型——Gemini Flash 2.0、R1 和 o3-mini,并重点介绍各自的性能、优势以及潜在应用场景。

一、模型背景与功能概述¶
1. 谷歌 Gemini Flash 2.0¶
- 模型定位
Flash 2.0 属于谷歌最新推出的基于大规模预训练的生成式语言模型,定位于在保持高准确度的同时大幅度降低推理成本和响应时间。 - 上下文窗口
最大可处理 100 万个输入 token,相比以往十万级别的上下文窗口有显著提升。在需要分析或总结超大规模文本时表现更加出色。 - 推理方式
拥有传统大语言模型的解码策略,不额外进行多回合“思考”推理过程,故而延迟极低。 - 官方定价(基于 OpenRouter 的参考报价)
- 输入:约 $0.10/百万 tokens
- 输出:约 $0.40/百万 tokens
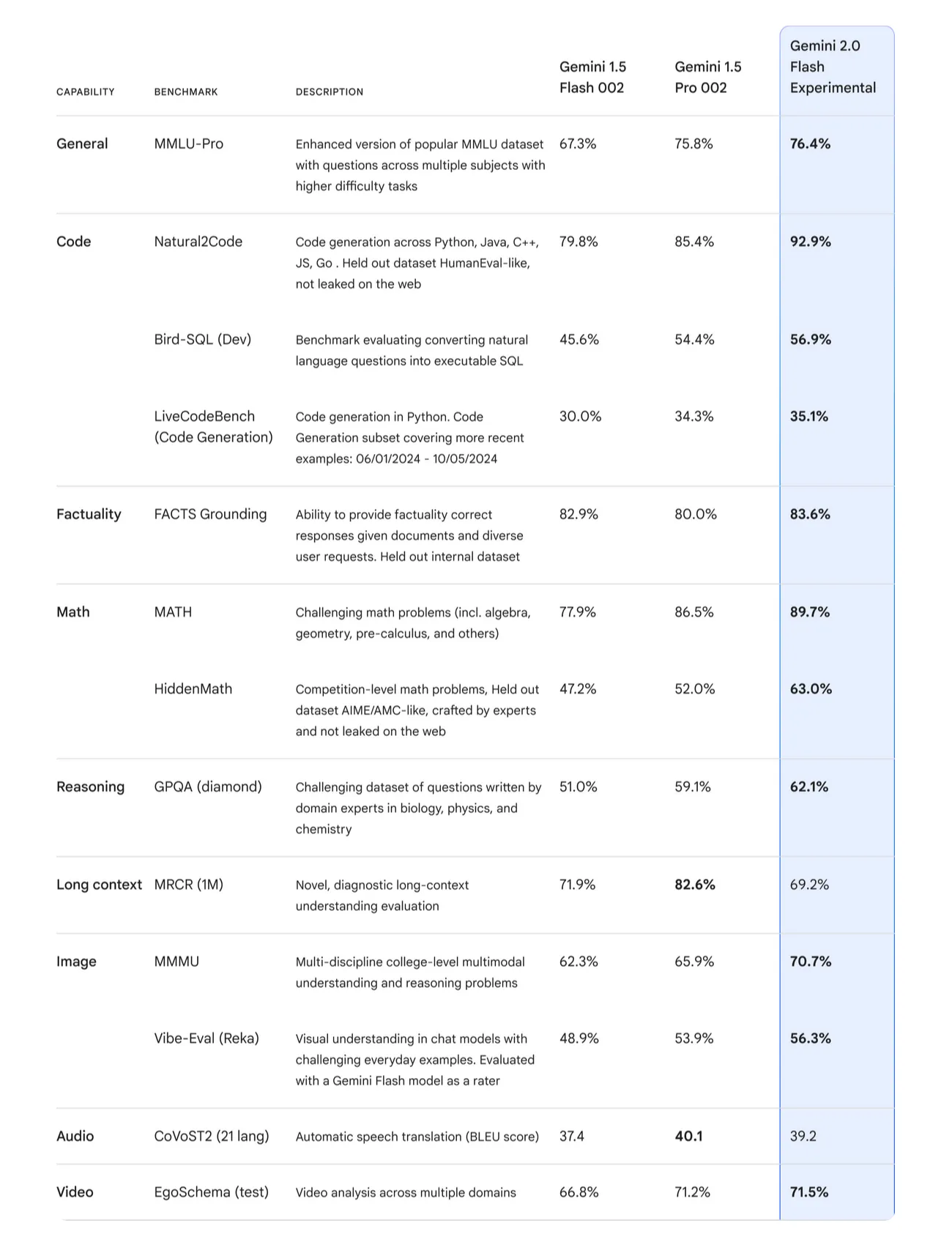
2. DeepSeek R1¶
- 模型定位
R1 是 DeepSeek 近些时间上线的关键推理模型,曾在推理深度、准确率等方面有突出表现,但存在速度与上下文限制方面的不足。 - 上下文窗口
约 128,000 tokens,相比同类主流大模型已经相对有限,在需要长文本上下文或多轮对话时可能出现瓶颈。 - 推理方式
通过多层级的“思考”实现更精细的语义理解,代价是推理速度较慢。 - 官方定价
- 输入:约 $0.75/百万 tokens
- 输出:约 $2.40/百万 tokens
3. OpenAI o3-mini¶
- 模型定位
作为 OpenAI 家族的中端模型,o3-mini 则倾向于在保证推理性能的前提下降低部分运营成本,比高端模型便宜,但依然不算“平价”选项。 - 上下文窗口
约 200,000 tokens,处于 R1 与 Gemini Flash 2.0 之间。 - 推理方式
和 GPT 系列相似,采用多步推理策略,每步思考后再生成最终回答,因而准确率表现相对稳定,但速度稍逊于纯串行生成方式。 - 官方定价
- 输入:约 $1.10/百万 tokens
- 输出:约 $4.40/百万 tokens

二、速度与准确度对比¶
在综合类或专门领域任务(如金融分析、代码生成)的实际使用中,速度与准确度往往是一体两面。以下通过具体的 SQL 查询案例对三款模型的响应速度与输出质量进行说明。
1. SQL 查询案例:计算相关性¶
测试问题:
“过去一年里,Reddit 的股票与 SPY 的收益率相关性是多少?”
- Gemini Flash 2.0
- 输出时长:数秒内完成
- 结果准确性:首次输出中拼写正确,无需修改即可执行,成功得到约 0.28 的相关系数
-
整体评分:1/1
-
DeepSeek R1
- 输出时长:约 30 秒甚至更久
- 结果准确性:出现
adjustedClosingPrice拼写错误,需手动改正后才能执行 -
整体评分:0.7/1
-
OpenAI o3-mini
- 输出时长:数秒至十余秒不等,比 R1 快但比 Flash 2.0 慢
- 结果准确性:未正确识别 Reddit 的真实股票代码,需手动修正后才能得到有效结果
- 整体评分:0.7/1
2. SQL 查询案例:营收增长筛选¶
测试问题:
“哪些生物科技公司在过去四个季度中,每季度的营收都呈增长趋势?”
- Gemini Flash 2.0
- 输出时长:依旧仅需数秒
- 结果准确性:生成的 SQL 一次通过,查询结果与手动评估较为吻合
-
整体评分:1/1
-
DeepSeek R1
- 输出时长:明显偏长
- 结果准确性:生成的 SQL 语句无法直接执行,需要对部分语句做大量修改
-
整体评分:0/1
-
OpenAI o3-mini
- 输出时长:中等偏快
- 结果准确性:基本正确,仅有少量形式上的瑕疵,查询效果良好
- 整体评分:1/1
三、成本与上下文窗口的影响¶
在大规模应用场景中(如金融数据库实时查询、企业内部文档检索等),上下文窗口的大小和调用成本是影响决策的重要因素。
| 模型 | 上下文窗口 | 输入成本 | 输出成本 | 综合速度 |
|---|---|---|---|---|
| Gemini Flash 2.0 | 1,000,000 tokens | $0.10/百万 tokens | $0.40/百万 tokens | 数秒级,极快 |
| DeepSeek R1 | 128,000 tokens | $0.75/百万 tokens | $2.40/百万 tokens | 30 秒级,极慢 |
| OpenAI o3-mini | 200,000 tokens | $1.10/百万 tokens | $4.40/百万 tokens | 数秒至十余秒,适中 |
分析上述数据可见:
- 上下文窗口:
- Flash 2.0 达到 100 万 tokens,在超大段文本处理和多轮对话场景中游刃有余。
- o3-mini 约 20 万 tokens,较传统 GPT 系列高,但仍不及 Flash 2.0。
-
R1 仅 12.8 万 tokens,可在中小规模文本分析中使用,但容易碰到上限。
-
成本:
- Flash 2.0:输入 $0.10/百万 tokens、输出 $0.40/百万 tokens,综合来看最为经济。
- DeepSeek R1:输入 $0.75/百万 tokens、输出 $2.40/百万 tokens,约为 Flash 2.0 的七倍。
-
o3-mini:输入 $1.10/百万 tokens、输出 $4.40/百万 tokens,约为 Flash 2.0 的十一倍,也是最贵的一款。
-
速度:
- Flash 2.0:基本可在数秒内生成完整答案,定位为快速响应场景。
- R1:依赖较长的推理,可能长达半分钟或更久,一些应用需要分段调用或异步处理,体验不佳。
- o3-mini:通过高效率推理框架,速度比 R1 快,但仍然略慢于 Flash 2.0。
四、行业应用与典型场景¶
- 金融分析与交易平台
- 需要快速响应的 SQL 查询、数据对比、图表生成等功能时,响应时间直接影响用户体验与数据时效性。
-
Flash 2.0 在这个场景中兼具速度与成本优势,适合海量查询与实时分析。
-
企业知识库与文档管理
- 大型企业常需对海量文档进行全文搜索与自动总结,上下文窗口越大,能一次性处理的文本内容越丰富。
-
Flash 2.0 的百万级上下文在处理长篇文档、年度报告、专利文档等方面更具优势。
-
多轮对话与智能客服
- 需反复调用模型,且对延迟要求高,希望控制调用成本。
- Flash 2.0 的低单次调用费用使得频繁交互成本更易控制。
-
R1 仍可用于对答逻辑严谨、需要深度推理的任务,但可能在延迟方面给用户造成等待时间过长的负面体验。
-
代码生成与调试
- 代码补全与问题诊断环节对于准确度和速度均有一定需求,特别在本地开发环境或 IDE 集成场景下,过慢的响应会降低开发效率。
- Flash 2.0 在生成 SQL、Python、Java 等多语言代码时,可快速给出可执行片段;o3-mini 也能提供高质量输出,但调用费用更高。
五、未来趋势与模型进化¶
- 精度与成本的进一步平衡
未来或将出现更多精细化蒸馏模型,在保留部分高准确度的同时,大幅降低计算资源的占用与调用成本。 - 混合推理架构的兴起
一些场景可采用“快速大模型 + 小规模推理模型”组合,将繁重任务拆分给多个模型分别处理,通过并行调用减少整体响应时间。 - 更灵活的上下文管理机制
随着用户对多模态输入、超长文本输入的需求不断增长,新一代模型会加强对智能切分、缓存机制等方面的支持,扩大可处理文本类型与长度。 - 行业间的激烈竞争
DeepSeek、谷歌与 OpenAI 并非该领域唯三,其他科技巨头与初创公司也在快速推出新型模型。竞争将进一步催生快速迭代,更优性能、更大上下文窗口及更低价格的方案有望持续涌现。
六、结语¶
综上所述,谷歌 Gemini Flash 2.0 以其极速响应、高准确度和极具竞争力的成本,在大型语言模型市场中形成了强大的冲击力。与之对比,DeepSeek R1 在准确率和上下文方面依然具备亮点,但速度慢与成本偏高的因素可能成为限制;OpenAI o3-mini 则介于二者之间,成本比 Flash 2.0 高,速度好于 R1,但不及 Flash 2.0 迅捷。
在具体应用中,应根据业务场景、资源预算、上下文规模需求、响应速度要求等方面进行选型。一些需要快速大规模调用的系统,如金融交易平台、实时交互式客服或文档搜索等,可优先考虑 Flash 2.0。若对深度推理能力或特定领域训练模型有更高要求,可以评估 o3-mini 或 R1 提供的多步推理潜力。随着技术的飞速发展,相信未来会出现更多融合高精度与高效率特性的创新模型,为各行各业带来更智能、更便捷的解决方案。